Finding similar data points in large datasets is a common challenge in many applications, including image search, recommendation engines, and document retrieval. This process, called nearest neighbor search, becomes much harder as datasets grow in size and the data itself becomes high-dimensional. Traditional methods that scan through each point are too slow and memory-hungry to work at scale.
Product quantization offers a way to overcome these limits. By compressing data into more manageable forms and simplifying comparisons, it provides fast and memory-efficient approximate search with good accuracy. It’s a practical method for systems that need both speed and scale.
How Nearest Neighbor Search Works?
Nearest neighbor search is the task of finding points in a dataset closest to a given query point, based on a measure like Euclidean distance or cosine similarity. In small, simple datasets, this is easy — just compare the query to every point and pick the closest matches. But things get messy as data grows. With millions of points in high-dimensional space, brute-force search slows and drains memory. Distances between points also become less meaningful in higher dimensions, a phenomenon called the “curse of dimensionality.” Finding truly similar neighbors becomes harder and more costly.
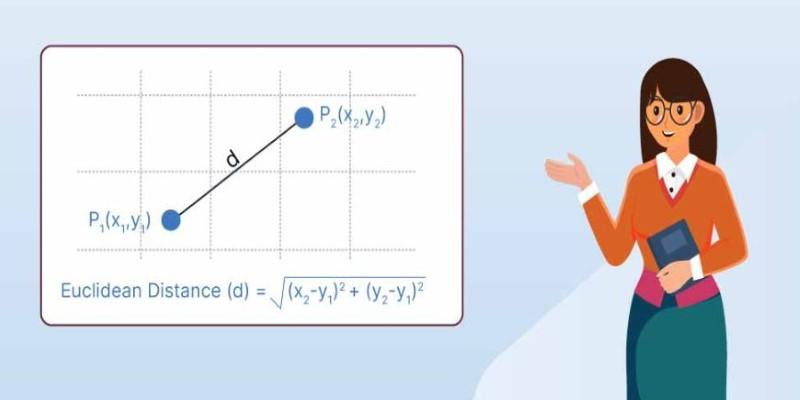
That’s where approximate nearest neighbor search comes in. Instead of guaranteeing a perfect answer, it delivers a very close result, but much faster and more efficiently. These methods are built on clever indexing and compression techniques, which cut down the number of comparisons needed without losing much quality. Among these, product quantization stands out. It compresses data intelligently, enabling fast searches with compact storage. This makes it especially useful for high-dimensional data in demanding settings, like large-scale image search or real-time recommendation systems, where speed and scalability matter.
How Product Quantization Improves Search?
Product quantization reduces the size of high-dimensional vectors by breaking them into smaller parts and encoding them compactly. This process preserves enough information to approximate distances between vectors while cutting down on storage and computation. The key idea is to split the full vector space into lower-dimensional subspaces, quantize each subspace separately, and represent each with a compact code.
For example, a 128-dimensional vector might be split into 8 smaller vectors, each 16 dimensions. In each subspace, a codebook is created — essentially, a set of representative vectors chosen through clustering. Every sub-vector is then replaced with the index of its closest representative in the codebook. This way, the full vector is represented by a sequence of small indices instead of full values. During search, distances between vectors are approximated by combining the precomputed distances between codebook entries.
This method has two strong benefits. It significantly reduces memory use because each vector becomes a sequence of small integers instead of a long list of floating-point numbers. It also speeds up distance calculations since most of the computation can be done through fast lookups in tables of precomputed distances. Product quantization allows very large datasets to fit in memory and be searched in real time, which is a big advantage for systems where storage and speed matter. Its design makes it especially effective for tasks involving millions of high-dimensional vectors.
Common Applications of Product Quantization
Product quantization is widely used in systems where large-scale similarity search is a core function. In image retrieval, for example, it allows systems to quickly find photos or visual patterns similar to a query image, even in databases containing millions of entries. In recommendation engines, it helps match users to products or content that aligns with their preferences by comparing high-dimensional feature vectors efficiently.
Search engines sometimes use product quantization to compare document embeddings, enabling faster retrieval of semantically similar documents. It’s also used in machine learning workflows to speed up tasks that involve comparing feature representations. The method’s flexibility makes it useful in many contexts where fast, approximate search is more valuable than slow, exact results. Its efficiency means that it can support interactive, real-time applications where users expect immediate responses even from huge datasets.
Trade-offs and Practical Considerations
As with any approximation, product quantization involves choices that balance accuracy with efficiency. The number of subspaces and the size of each codebook are key parameters. Using more subspaces and fewer codewords per subspace creates more compact representations, which saves memory and speeds up search. But this can also reduce precision, because the quantized representation becomes less exact. Choosing the right settings depends on the application and how much error is acceptable for the speed gains.
The quality of product quantization also depends on the nature of the data. If the data is unevenly distributed or highly clustered, the approximation might not perform equally well across all regions. Some systems improve results by refining how codebooks are trained, or by combining product quantization with other indexing techniques like inverted files to keep the approximation tight.
Training the product quantizer is another consideration. Building the codebooks requires clustering on the dataset, which can take time and memory. However, this cost is only paid once during setup. After training, the quantizer can be used repeatedly for fast searches. Another strength of product quantization is its flexibility: it can work with different distance metrics, although it’s most often used with metrics that remain meaningful in high-dimensional spaces, like Euclidean distance. Its ability to scale effectively while delivering approximate results that are good enough for many tasks makes it popular in search-heavy applications.
Conclusion
Product quantization offers a practical solution for handling large-scale nearest neighbor search in high-dimensional spaces. By compressing data into compact codes, it reduces memory use and speeds up search without losing too much accuracy. This makes it ideal for applications like image retrieval and recommendation systems that need fast responses over massive datasets. While it involves some trade-offs in precision, its balance between efficiency and quality has made it widely adopted. Understanding how product quantization works helps developers build systems that deliver quick, scalable search results without overwhelming hardware resources or sacrificing performance.











